
算力平台:
导入模型
目录
从 Safetensors 权重导入微调适配器
首先,创建一个 Modelfile,其中包含一个指向你用于微调的基础模型的 FROM 命令,以及一个指向你的 Safetensors 适配器目录的 ADAPTER 命令:
dockerfile
FROM <base model name>
ADAPTER /path/to/safetensors/adapter/directory确保你在 FROM 命令中使用与创建适配器时相同的基模型,否则你会得到不一致的结果。大多数框架使用不同的量化方法,因此最好使用非量化(即非 QLoRA)适配器。如果适配器与你的 Modelfile 在同一目录中,使用 ADAPTER . 来指定适配器路径。
现在从创建 Modelfile 的目录中运行 ollama create:
bash
ollama create my-model最后,测试模型:
bash
ollama run my-modelOllama 支持基于几种不同的模型架构导入适配器,包括:
- Llama(包括 Llama 2、Llama 3、Llama 3.1 和 Llama 3.2);
- Mistral(包括 Mistral 1、Mistral 2 和 Mixtral);和
- Gemma(包括 Gemma 1 和 Gemma 2)
你可以使用能够输出 Safetensors 格式适配器的微调框架或工具来创建适配器,例如:
从 Safetensors 权重导入模型
首先,创建一个 Modelfile,其中包含一个指向包含你的 Safetensors 权重的目录的 FROM 命令:
dockerfile
FROM /path/to/safetensors/directory如果你在权重文件所在的同一目录中创建了 Modelfile,你可以使用命令 FROM .。
现在从你创建 Modelfile 的目录中运行 ollama create 命令:
shell
ollama create my-model最后,测试模型:
shell
ollama run my-modelOllama 支持导入多种不同架构的模型,包括:
- Llama(包括 Llama 2、Llama 3、Llama 3.1 和 Llama 3.2);
- Mistral(包括 Mistral 1、Mistral 2 和 Mixtral);
- Gemma(包括 Gemma 1 和 Gemma 2);以及
- Phi3
这包括导入基础模型以及任何与基础模型 融合 的微调模型。
导入基于 GGUF 的模型或适配器
如果你有一个基于 GGUF 的模型或适配器,可以将其导入 Ollama。你可以通过以下方式获取 GGUF 模型或适配器:
- 使用 Llama.cpp 中的
convert_hf_to_gguf.py脚本将 Safetensors 模型转换为 GGUF 模型; - 使用 Llama.cpp 中的
convert_lora_to_gguf.py脚本将 Safetensors 适配器转换为 GGUF 适配器;或 - 从 HuggingFace 等地方下载模型或适配器
要导入 GGUF 模型,创建一个 Modelfile,内容包括:
dockerfile
FROM /path/to/file.gguf对于 GGUF 适配器,创建 Modelfile,内容如下:
dockerfile
FROM <model name>
ADAPTER /path/to/file.gguf在导入 GGUF 适配器时,重要的是使用与创建适配器时所用的相同基础模型。你可以使用:
- Ollama 中的模型
- GGUF 文件
- 基于 Safetensors 的模型
一旦你创建了 Modelfile,请使用 ollama create 命令来构建模型。
shell
ollama create my-model量化模型
量化模型可以让你以更快的速度和更少的内存消耗运行模型,但精度会有所降低。这使得你可以在更 modest 的硬件上运行模型。
Ollama 可以使用 -q/--quantize 标志与 ollama create 命令将基于 FP16 和 FP32 的模型量化为不同的量化级别。
首先,创建一个包含你希望量化的 FP16 或 FP32 基础模型的 Modelfile。
dockerfile
FROM /path/to/my/gemma/f16/model使用 ollama create 来创建量化模型。
shell
$ ollama create --quantize q4_K_M mymodel
transferring model data
quantizing F16 model to Q4_K_M
creating new layer sha256:735e246cc1abfd06e9cdcf95504d6789a6cd1ad7577108a70d9902fef503c1bd
creating new layer sha256:0853f0ad24e5865173bbf9ffcc7b0f5d56b66fd690ab1009867e45e7d2c4db0f
writing manifest
success支持的量化方式
q4_0q4_1q5_0q5_1q8_0
K-means 量化方式
q3_K_Sq3_K_Mq3_K_Lq4_K_Sq4_K_Mq5_K_Sq5_K_Mq6_K
在 ollama.com 上分享你的模型
你可以通过将模型推送到 ollama.com 来分享你创建的任何模型,以便其他用户可以尝试使用。
首先,使用浏览器访问 Ollama 注册 页面。如果你已经有账户,可以跳过这一步。
用户名 字段将作为你模型名称的一部分(例如 jmorganca/mymodel),因此请确保你对所选的用户名感到满意。
现在你已经创建了帐户并登录,请前往 Ollama Keys 设置 页面。
按照页面上的说明确定你的 Ollama 公钥的位置。
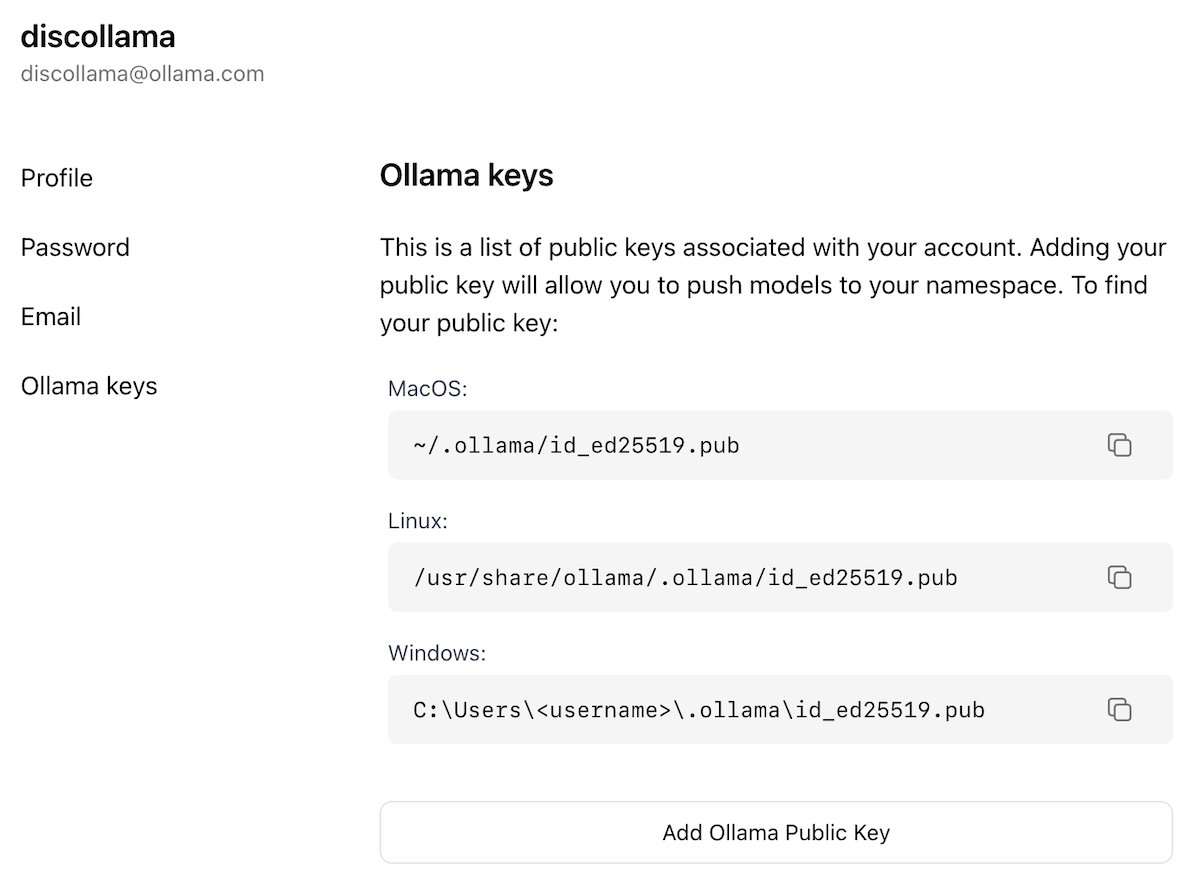
点击 Add Ollama Public Key 按钮,将你的 Ollama 公钥内容复制并粘贴到文本框中。
要将模型推送到 ollama.com,首先确保模型名称正确包含你的用户名。你可能需要使用 ollama cp 命令将模型复制并重命名。一旦你对模型的名称满意,使用 ollama push 命令将其推送到 ollama.com。
shell
ollama cp mymodel myuser/mymodel
ollama push myuser/mymodel一旦你的模型被推送后,其他用户可以通过以下命令拉取并运行它:
shell
ollama run myuser/mymodel